


2024年5月28日
「AI時代の知的財産権検討会」中間とりまとめ案で、AI議論を追いかける
弁護士 出井甫 (骨董通り法律事務所 for the Arts)
◆はじめに
2023年6月28日に、筆者はこちらのコラムで、これから国内外で本格的にAIと著作権、AIガバナンスに関する議論が始まるとお伝えしました。
そして同年10月4日から、知的財産戦略本部は、上記テーマを扱う有識者会議「AI時代の知的財産権検討会」を開催しています(筆者は、内閣府知的財産戦略推進事務局参事官補佐として加わっていました)。この検討会では、著作権に限らず、生成AIと知財をめぐる懸念やリスクなどの対応について広く議論されています。
そこで、本コラムでは、2024年4月に公表されたその「中間とりまとめ(案)」(以下「中間とりまとめ案」)を俯瞰し、AI議論の状況を把握してみたいと思います。
⇒【追伸】本コラムが公開されて間もなく、「案」のとれた「中間とりまとめ」が公開されました。変更点はほとんどありませんので、以下の内容は、最終版の俯瞰にもなります。
目次
1 生成AIと著作権法
2 生成AIと著作権法以外の知的財産法
3 技術による対応
4 契約による対応
5 個別問題
(1)労力・作風の保護
(2)声の保護
(3)デジタルアーカイブ整備
(4)ディープフェイク
6 横断的見地からの検討
7 AI技術と特許審査実務
◆ おわりに
1 生成AIと著作権法
まず、著作権法との関係では、前回コラムで取り上げた、3つの論点(①学習行為の適法性、②AI生成物が学習データと類似した場合における侵害の成否、③AI生成物の著作物性)が中心に言及されています。
実際の議論は、文化庁主催の審議会で行われていますので、中間とりまとめ案では、その報告書「AIと著作権に関する考え方」の一部が引用されています。
検討された内容はどれも重要ですが、以下は特に実務に影響が出ると予想しています(頁数は上記考え方の掲載場所です)。
①学習段階
まず、享受*目的と非享受目的が併存する場合、著作権法30条の4は適用されないことが確認されています(19頁~)。また、その該当例として、意図的に学習データに含まれる著作物の全部・一部を出力させる目的で学習する行為などが挙げられています。
著作物が現に出力されているかではなく、「著作物を・・出力させる目的」があるかによって享受目的の有無が判断されますので、たまたま著作物と類似するAI生成物が出力されるだけでは足りず、その頻度や、類似物の出力を防止する措置がとられているかなどの事情も考慮されると思われます。
*享受:著作物等を観たり聴いたりして、精神的欲求を満たすことを意味します。
一方、作風レベルで類似する生成AIの開発は、30条の4の適用範囲内であることが明示されました(21頁~)。
従前、大量に作風の似た作品が出力される生成AIの開発が、30条の4但書に該当するかが議論されていましたが、ここでは該当しない方針で整理されています*。
もっとも、作風と表現との区別は容易ではありません。そのため、例えば、作風を似せる生成AIを開発したとしても、その出力結果に著作物が含まれているとして、享受目的があると認定されるリスクが残る点には留意が必要です。
*なお、文化審議会では、作風が類似する大量のAI生成物が生じることで、特定のクリエイターや著作物の市場と衝突してしまう場合は、但書に該当し得るという意見は出ていました。
その30条の4但書に関しては、データベースの著作物が販売されていなくとも、複製防止措置等により将来販売される予定があると推認される場合も但書に該当し得ることが示されました(26頁~)。
以前の文化庁の解説では、但書の適用例として、情報解析用のデータベースの著作物が販売されている場合のみが挙げられていましたが(9頁)、それに追加された形になります。今回もデータベースの著作物を対象としていますので、それ以外の著作物への適用可能性は限定的かもしれません。ただ、引き続き動向は注視したいと思います。
その他、海賊版を学習する者は、生成利用段階で侵害物が生じた場合、その侵害の責任主体となり得ることが指摘されています(27頁~)。
AI生成物は、学習データを基に出力されますので、海賊版を学習した場合、それと類似した侵害物が出力される可能性が高まるという意味でも、避けるべき行動でしょう。
なお、別の箇所では、海賊版に限らず、侵害物の出力頻度や、出力防止措置の有無等によっては、AI開発事業者も著作権侵害の責任主体になり得ると記載されています(36頁~)。この判断要素は、前記享受目的の有無とリンクするように思われます。そのため、仮にAI開発事業者が責任主体となる場合、著作権法30条の4の適用も否定される(すなわち学習も違法と判断される)可能性があります。
②生成利用段階
この項目で特筆すべきは、AI利用者が学習元となった著作物を認識していなくとも、その著作物を生成AIが学習していた場合には、依拠性が肯定される見解が明示されたことです(33頁~)。
従前、生成AIのユーザーが学習データを知らないまま、既存の著作物と類似するAI生成物が出力させた場合、依拠性が認められるかが論点となっていました。すなわち、依拠性の判断主体を、人とするか、AIとするかという問題です(前回コラム参照)。
今回は、人とAIを併用する見解が示されました。そのため、例えば、AIが学習していなくとも、ユーザーが既存の著作物を認識していた場合、依拠性が肯定されます。また、前記のようにユーザーにとって、たまたま類似したAI生成物が出力された場合でも、依拠性が肯定され、著作権侵害となり得ます。
今後、AI生成物の用途にもよりますが、生成AIへの指示・入力や出力内容の精査が、一層求められるように思います。
③AI生成物の著作物性
この項目では、AI生成物の著作物性が、人の創作的寄与を肯定する事情がどの程度積み重なっているかを総合的に考慮して判断されること、またその際には以下の要素が考慮され得ることが示されました(39頁~)。
➤ 指示・入力(プロンプト等)の分量・内容
➤ 生成の試行回数
➤ 複数の生成物からの選択
➤ 人間による加筆・修正の有無(但し、それ以外の部分には影響しない)
各考慮要素の評価の仕方は、前回コラムに記載した内容と概ね同じようです。
なお、私見では、AI生成物が著作物と認められるためには、相当具体的な指示・入力が必要と考えます。現在の生成AIは、WordやPhotoshopなどと比べて出力結果の予測が難しく、偶然的な側面があるからです。もしその作業が面倒な場合は、著作物性を持たせたいのであれば、人の手で十分に加工編集する方法が無難な対応かと思います。
2 生成AIと著作権法以外の知的財産法
中間とりまとめ案では、著作権法のほか、意匠法、商標法、不正競争防止法(商品等表示、営業秘密、限定提供データ、商品形態)、肖像権、パブリシティ権との関係で、生成AIを用いた場合に特有の論点などが生じないかが報告されています。
検討項目は、他人の知的財産等(商標や意匠など)の学習・生成利用の適法性、法的保護(生成物の当該法による保護)の可否です。結果は、概ね以下のように整理できそうです。
| 学習の適法性 | 生成利用の適法性 | 法的保護の可否 | |
| 意匠法 | ○ | ― | 創作的寄与の有無 |
| 商標法 | ○ | ― | 可 |
| 商品等表示 | ○ | ― | 可 |
| 営業秘密 | ― | ― | 可 |
| 限定提供データ | ― | ― | 可 |
| 商品形態 | 〇 | 依拠性の有無 | 可 |
| 肖像権 | ― | ― | N/A |
| パブリシティ権 | ― | ― | N/A |
〇:違法となる可能性は低い
―:従来の考え方に基づき適法性を判断
可:従来の考え方に基づき要件を満たせば保護され得る
N/A:検討対象外
まず、他人の知的財産等を学習することについて、意匠法、商標法、不正競争防止法上の「商品等表示」「商品形態」との関係では、そもそも権利や規制が及ぶ可能性は低いと報告されています。一方、同法上の「営業秘密」や「限定提供データ」、肖像権、パブリシティ権との関係では、特有の論点はなく、従前と同じ考え方により、適法性が判断されるようです。
次に、他人の知的財産等を含むAI生成物を生成利用した場合の適法性については、不正競争防止法上の「商品形態」の模倣に、依拠性が必要とされていますので、前記著作権法に関する議論が応用されると考えられています。例えば、AIが対象商品にアクセスしているのであれば、(ユーザーが学習データを認識していなくとも)依拠性が肯定されます。その他の関係では、特有の論点はなく、従前と同じ考え方により、適法性が判断されるようです。
そして、法的保護の可否については、意匠法上、「意匠」は、人が創作したものであることが必要と考えられています。そのため、AI生成物が意匠法によって保護されるには、前記著作権法と同様に、創作的寄与の有無が論点となり得ます。その他の関係では、特有の論点はなく、従来の考え方により、各法の要件を満たすことで保護され得ることが報告されています。
3 技術による対応
生成AIと知的財産権をめぐる懸念・リスクへの技術的な対応として、考えられる技術例や留意点なども報告されています。
例えば、前回コラムで述べた通り、現在、生成AIの精度が高く、外見上、AI生成物と、人が制作したものとを区別することが難しくなることが懸念されています。
これに対応する技術として、AIが生成されたコンテンツを利用者が識別できる仕組みが紹介されています。例えば、AI生成物であること等の表示、生成AIサービスの出元情報の付与、AI生成物であることを検知するサービスです。
いずれも有用そうですが、未だ表示を付すべき「AI生成物」の範囲をどうするか、またAI生成物を改変した場合にも技術が上手く機能するかは不確定です。更に、外観上、AI生成物であることが分かったとしても、著作権が発生しない「AI創作物」であるかどうかまで判別できるとは限らない点には留意が必要です。
次に、AI生成物が既存の著作物と類似した場合に著作権侵害のリスクが存在することに対応する技術として、フィルタリング(他のコンテンツとの類似性を判定し、又は侵害のおそれのあるAI生成物の出力などを抑制する技術)が挙げられています。
前者は、Google、Bing、Yahoo!などの検索エンジンにおける検索機能で、後者は、画像生成AI「DALL-E3」等で採用されています。
留意点としては、AIの判定結果が、法的な類似性の判断と一致しない可能性があることです。そのため、AI生成物を利用する場合、やはり最終的には、人によるチェックを介在させた方が良さそうです。
そして、前述の通り、AI生成物が他人の作風と類似するに留まる場合は、著作権法30条の4の適用範囲内と考えられていますが、著作権者の中には、自身の作品が無断で学習されること自体への懸念や不安を抱いている方がいます。
その対策として、自動収集プログラム(クローラ)による収集を拒絶する技術が挙げられています。例えば、インターネット上のファイルに「robots.txt」を記載する方法や、IDやパスワード等によってアクセス制限を設ける方法です。
課題として、前者は、「robots.txt」付きファイルの収集を回避するという、クローラーの自主的な慣行で成り立っていますので、これを無視するクローラーには通用しません。また、後者は、アクセス制限を回避すると、不正アクセス禁止法違反による処罰の対象となり得ますが、公開用コンテンツには不向きという側面があります。
上記懸念や不安に対しては、画像に特殊な画像処理(学習を妨害するノイズ)を施すことで学習を妨げる技術も紹介されています。このノイズによって、AIは、画像認識できなくなるようです。有用そうですが、その分、他人の画像に無断でノイズを加えるといった悪用には注意が必要そうです。
最後に、ある学習が著作権侵害であるかどうかの検証や、仮に侵害である場合にその侵害物を除去するには、学習元コンテンツを追跡したり、それを学習済モデルから除外する技術が必要と思われます。
ただ、そうした技術は未だ研究段階であったり、一般的に困難とのことです。
・・そうすると、著作権法30条の4の該当性に疑いのある生成AIを見かけたとしても、内部検証はできず、侵害と判断されてもそれを除去するのが難しいというのが現状です。
果たしてこれで良いのか、疑問です。
法的な整理ができても、それに見合った実務対応ができない状態は、早急に改善すべきでしょう。将来の技術開発を待つだけでなく、開発を支援するとか、開発者に学習用データセットの保全を促すとか、今できる対策を更に検討したいところです。
4 契約による対応
著作権法30条の4は、権利制限規定のうち、権利者の利益を害さない類型(第1層)に分類されています。そのため、中間とりまとめ案では、学習に伴い、権利者に対価を還元する法制度を設けることは難しいとの見解が示されています。
他方で、開発事業者がクリエイターの良質なデータを学習するために、権利者と合意の上で対価還元を行うことは(理論的には許諾や対価が不要でも)法的に可能であると報告されています。
その上で、考えられる方策例として、クリエイターが、生成AIへの追加学習(ファインチューニング)のために良質なデータを有償で提供することや、クリエイターが学習済みモデルを作成し、又は自ら開発した生成AIを販売することなどが紹介されています。既に、ShutterstockやGetty Imagesなどは、学習データを提供した方に対して、報酬を支払う取り組みをなされているようです。
こうした対価還元は、クリエイターの新たな創作への動機付けになる効果がありそうです。その際には、やはり第三者による無断学習の防止や、学習過程の追跡・侵害物を除去する技術が求められるように思います。
5 個別問題
AIが学習するものは、著作物に限らず、事実やデータ、作風なども含まれます。
そして、これらは、「創作的表現」とは異なるため、著作権法による保護が困難と考えられています。
もっとも、労力を費やして取得した情報や、汗水流して見につけた技能が、生成AIによってあっという間に模倣されてしまうのは、頑張った方にとって惜しいことです。
こうした懸念に対して、中間とりまとめ案では、不正競争防止法上の「営業秘密」「限定提供データ」「商品等表示」「商品形態」や、一般不法行為による保護の可能性が説明されています。
ただ、前者は、労力や作風そのものを保護する制度ではありません。後者についても、過去の裁判例を見ると、一般不法行為が成立するのは、問題となる行為が「社会的に許容される限度を越えた」場合や「著作物の利用による利益とは異なる法的に保護された利益を侵害するなどの特段の事情」がある場合が念頭に置かれています(知財高判平成17年10月6日【ヨミウリ・オンライン(YOL)事件】、最判平成23年12月8日【北朝鮮事件】)。
そのため、現状、労力・作風を、法的に保護するには限界があるとしています。その上で、中間とりまとめ案では、他の方法が提案されています。この点は、後の項目「6 後段的見地からの検討」で説明いたします。
昨今、声優などの声を無断で生成AIに学習させて、その方の合成音声を出力させている事例が見受けられます。そこで検討会では、声の法的保護についても議論されました。
まず、肖像権については、文言上、「肖像」に「声」を含めることは難しいとされています。一方、パブリシティ権が対象とする「肖像等」には「声」が含まれることから、声を商用利用されている場合には、一定の要件のもと、パブリシティ権によって保護し得る場合があると示されています。
また、声そのものではありませんが、歌声であれば「実演」として著作隣接権が、指定商品又は役務の範囲であれば音商標として商標権によって保護され得ることが確認されています。但し、学習に対して権利が及びにくい点は前述の通りです。
なお、声がなりすましに使用された場合には、詐欺罪、名誉毀損、名誉感情侵害などによる法的責任が生じ得ることも、保護する手段として取り挙げられています。
私見では、商用利用以外の場合にも、声は保護され得ると思っています。声も人格を構成する重要な要素だからです。例えば、中国の法律では、声が肖像と同様に保護されることが規定されています(民法1023条2項)。
今までは、声の悪用があまり問題となっていなかっただけであり、実際には、営利目的に限らず、肖像権に似た権利、いわば「声音権」なるものが観念できると考えています。今後、声の権利について研究を深めたいと思います。
美術館や博物館などが有しているデジタルアーカイブは、生成AIの学習用データセットとして利用できる可能性があるようです。その用途は、まだ明確に示されていませんが、貴重なデータはAI技術開発にとって有用そうです。
他方で、デジタルアーカイブには、他者の権利が含まれていることがあります。また、むやみに学習素材とすることには、権利者側の懸念も指摘されています。
そのため、まずは、権利処理が完了しているものや、国や地方公共団体が権利を保有しているものを、データセットとして活用する方向性などが確認されています。
今後、デジタルアーカイブからどんなデータセットが生まれるのか、注目です。
声のみならず、現在、ディープフェイク*の悪用も問題となっています。
その救済方法として、例えば、他人の著作物が利用されている場合には、著作権や著作者人格権侵害、実演の改変が確認できる場合は実演家人格権侵害を主張することが挙げられています。また、被写体の肖像や氏名が使用されている場合は、肖像権、パブリシティ権、氏名権侵害も視野に入ってくるでしょう。
*生成AIで、実在の人物、物体、場所その他の存在物や事象に類似させたり、ある人物が本物又は真実であるかのように偽って表示し得るものを意味します。
その他、ディープフェイクによって、無断で肖像を異なる動画に合成されられた事案において、名誉毀損罪の成立を認めた裁判例もあります(東京地判平成18年4月21日(平成17年(刑わ)第5073号))。
一方、諸外国では、ディープフェイクへの対策として、偽情報の拡散を規制する立法措置がとられています(例えば、米国では個別の州法が、EUでは包括的に規制するAI規則が今年5月21日に成立しています。)。それ故、中間とりまとめ案では、ディープフェイクを、知的財産権の分野を超える問題として議論すべきとされています。
6 横断的見地からの検討
ご覧の通り、生成AIに関する不安や懸念の全てを、法のみで解決することが難しいのが現状です。
ではどう対応すべきでしょうか。中間とりまとめ案では、法の理解を土台としつつ、法・技術・契約の相互補完的な活用が提案されています。
例えば、著作権法30条の4によって許諾なくして著作物を学習することが可能なもの(データや事実、作風を含む画像など)でも、開発者と権利者との間で有償で提供する契約を締結し、かつ技術によって複製等を防ぐことで、その流通をコントロールすることが挙げられています。
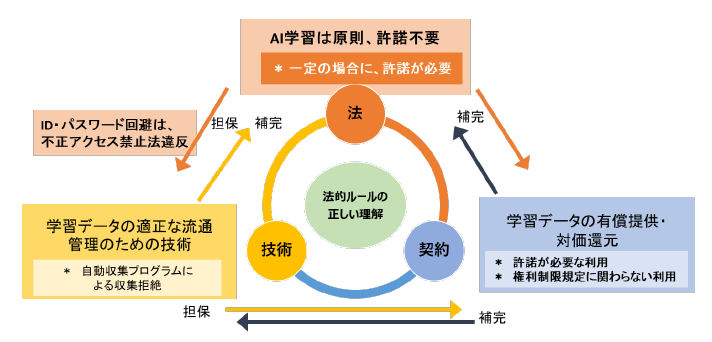 知財本部「中間とりまとめ(案)」70頁
知財本部「中間とりまとめ(案)」70頁
また、この相互補完的スキームを実装するため、各主体(AI開発者、AI提供者、AI利用者、権利者など)に期待される取組例が、ずらっと紹介されています。ここでは紙面の都合上、省略しますが、みなさまに何が期待されているか、閲読されてみてください。
この期待の対象は、AIに対する不安や懸念の性質上、国内のステークホルダーに限られません。そのこともあり、中間とりまとめ案では、日本がAIビジネスの国際展開を促進するためにも、国際的に統一されたルール形成に主体的に参画し、推進する必要性も示されています。
今後、日本が、学習に用いるデータの基準やデータの識別方法などの国際ルール形成や国際標準化に必要な論点や方向性を提供し、リードできることは、各不安や懸念の解決にもつながり得ると考えます。
ただ、前述の通り、上記スキームの要である技術は、未だ発展途上です。また、どのくらいの方が推奨される契約を締結するかは不確定です。特に海外の事業者やユーザーが、このスキームにのってくるかは読めないところがあります。
功を奏するかどうかは、最終的には、生成AIに関わる方の意思にかかっていると思います。(この点は、ガバナンス手法について触れたこちらが参考になるかもしれません。)
7 AI技術と特許審査実務
現在、AIは、材料科学や創薬分野などの発明創作過程にも活用されています。
その際、特許法上の「発明」の主体である「発明者」に、AIが含まれるかかが問題となります。
今のところ、日本を含む諸外国は、AIは「発明者」には該当しないという認識で共通しているようです。
現に、昨今、米国在住のAI研究者が、DABASと称するAIを発明者として各国で特許出願をしていますが、その多くで拒絶されています。日本でも、今月、「発明者」は自然人に限定されるという理由で、DABASの登録を否定する判決がでました(令和6年5月16日・令和5(行ウ)5001号)。
その他、例えば、AIが出力した説明を根拠に特許出願をした場合(例えば、ある化学物質の機能の説明をAIの出力値で代替する場合など)に、実施可能性(当業者が実施可能な程度に、発明の詳細な説明に、発明内容が明確かつ十分に記載されていること)やサポート要件(特許請求の範囲の記載に、発明の詳細な説明が記載されていること)が認められるかも検討事項とされていました。
結論として、AIが出力した情報というだけでは、各記載要件としては不十分であり、従前通りの特許審査実務で対応することが確認されています。
◆おわりに
以上、中間とりまとめ案を見てきました。
課題から対策までいろいろが紹介されていますね。これから更にAIに関する課題がでてくるかもしれませんが、悩んだり、挑戦することこそ、AIにはない人の妙味なんだと思います。
人間は考える葦とは、こういうことでしょうか。
本コラムが、AI議論を追いかける一助となれば幸いです。
以上
■ 弁護士 出井甫のコラム一覧
■ 関連記事
AIと著作権・AIガバナンスについて考える(前編)
知的財産推進計画2023・海外の動向
2023年6月28日 弁護士
出井甫(骨董通り法律事務所 for the Arts)AIと著作権・AIガバナンスについて考える(後編)
国際的なAIガバナンス・現状分析
2023年7月26日 弁護士
出井甫(骨董通り法律事務所 for the Arts)「AI自動創作の現在を俯瞰する
~人工知能は実際どの程度電気羊の夢を見ているのか?~」
2017年6月26日 弁護士
福井健策(骨董通り法律事務所 for the Arts)「概説AI法」
2025年9月24日 弁護士 小山紘一(骨董通り法律事務所 for the Arts)
法的若しくは専門的なアドバイスを目的とするものではありません。
※文章内容には適宜訂正や追加がおこなわれることがあります。
